








The metaverse, a virtual realm that goes beyond traditional boundaries, will redefine how we interact and engage with digital environments. As this futuristic landscape continues to evolve, it becomes increasingly clear that real-time communication is at the heart of its immersive experience. In this blog post, we will delve into the transformative power of Real-Time Interaction (RTI) capabilities, which elevate the concept of real-time communication to new heights within the metaverse. We will explore three key technological advancements that drive this RTI evolution: the capabilities of massive live co-hosting for thousands of users, the real-time status synchronization of multi-guests, and the development of virtual avatar. We will uncover the key technical capabilities of real-time interaction (RTI), that enable enhanced interactivity and pave the way for a truly immersive metaverse experience.
Massive live co-hosting for 10,000+ (participants)
We believe that if too many participants speak at the same time, the voices will become unclear. This limitation is often due to technical considerations rather than product management decisions. When multiple participants activate their microphones, their audio and video streams need to be published from the client to the server, and a large number of participants can put a significant strain on the server. Therefore, traditional RTC approaches limit the number of participants speaking simultaneously in the same room, either on the business side or within the SDK.

ZEGOCLOUD RTI, on the other hand, does not impose such limitations on the number of simultaneous speakers. So, is this massive live co-hosting capability useful? The answer is yes. For example, in online events or online concerts with a massive audience of thousands of participants , we not only need to hear the performers’ voices but also the voices of many audience members. The capability of massive live co-hosting for 10,000+ is extremely valuable as it creates an authentic atmosphere and immersion.
Architectural Evolution
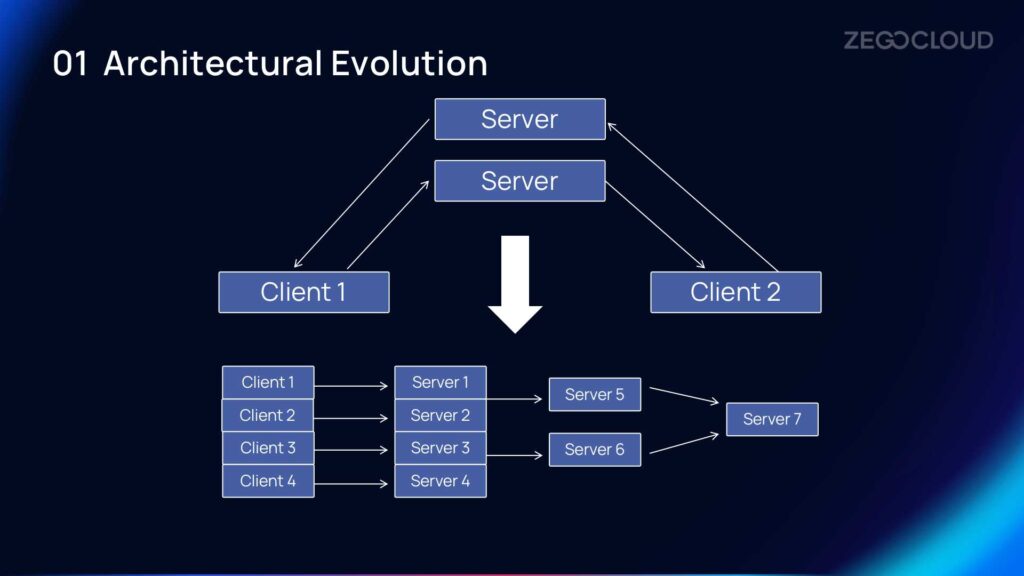
The traditional method of publishing audio and video streams from the client to the server and then forwarding them is not feasible for architectures like massive live co-hosting for 10,000+ participants. Instead, ZEGOCLOUD RTI publishes the audio and video streams from the client to the server, where they are routed and converged at edge nodes, and then played back to the clients. The audio received encompasses the information from all active speakers, ensuring the maximum realism and atmosphere.
Service Framework and Responsibilities
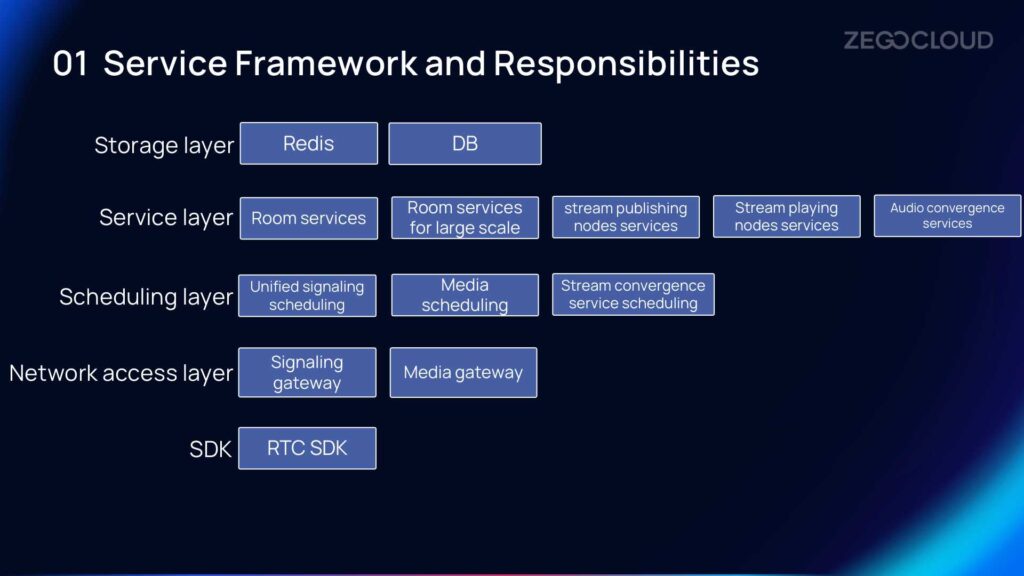
The overall service framework and responsibilities include the SDK, network access layer, scheduling layer, service layer, and storage layer.
Massive live co-hosting for 10,000+ requires a corresponding client SDK for integration, which includes signaling and media gateways. The scheduling layer consists of unified signaling scheduling, media scheduling, and stream convergence service scheduling. The service layer includes room services, room services for large scale, stream publishing nodes services, stream playing nodes services, and audio convergence services.
Overall Service Architecture
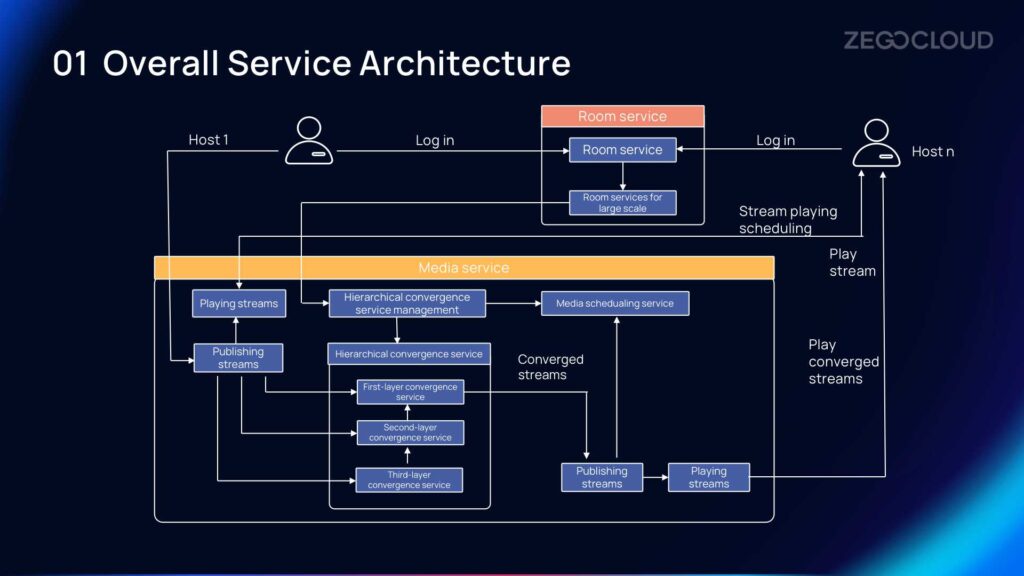
Next, let’s focus on the overall service architecture of massive live co-hosting for 10,000+.
This simplified architecture diagram shows two hosts, Host 1 and Host n. The majority of the services are related to the room, while the other part focuses on media services. To engage in co-hosting, participants must have a common room ID, and regardless of the number of participants in the room, users need to log in first. Logging in refers to obtaining room services, which maintain users’ login information.
During co-hosting, the media streams are published from the client-side to the server-side. When the number of participants is small, the media scheduling plays the streams directly from the source station without involving the convergence service mentioned earlier. However, when the room reaches a large number of participants, the previously established large room and hierarchical convergence services come into play. The large room caches and distributes the media stream information, and the convergence service aggregates the streams based on routing conditions at each layer.
ZEGOCLOUD has designed a three-layer convergence service, and all the data is ultimately converged at the stream publishing nodes. After going through the scheduling layer’s exit, the streams are played using the stream playing scheduling and then delivered to the converged streams through stream playing nodes, enabling massive live co-hosting for 10,000+ participants.
Client Architecture

Although the corresponding client-side interfaces and capabilities may appear simple, many aspects are actually handled on the server-side. The client-side also plays a role in stream scheduling, routing, audio deduplication in exceptional cases, audio-visual synchronization, and user information retrieval.
Challenges

The capability to enable massive live co-hosting actually poses significant technological challenges.
- High concurrency: Through improvements, ZEGOCLOUD can now support up to 1 million simultaneous online users in a single room.
- Massive convergence of network traffic and computational load: ZEGOCLOUD separates audio and video streams, converging only the audio streams. To alleviate the computational load, the client-side performs a certain amount of pre-computation on large data, ensuring that the server does not need to perform calculations again and can directly perform routing.
- Ensuring smooth audio without any dropped frames: ZEGOCLOUD prioritizes the integrity of audio data in each routing stage to prevent interruptions caused by routing strategies.
Real-Time Status Synchronization of Multi-Guests
Overview of Status Synchronization Capability

Real-time status synchronization of multi-guest is common in RTI of metaverse scenario. However, in the metaverse, user status encompass much more complex and diverse data, including movement status, virtual avatar actions, facial expressions, and item status. The synchronization of these status also requires real-time updates; otherwise, it would hinder smooth interaction and compromise the user experience.
Currently, ZEGOCLOUD achieves real-time signaling with a delay of around 60ms. It is because its globally unified real-time monitoring and scheduling of signaling, allowing for proximity-based edge node access.
To ensure better user experience in virtual world, the concept of user perspective is introduced on the server-side. The server can dynamically obtain the field of view of the virtual character based on its current position, and provide real-time event notifications to the client with relevant visual information. This allows the client to integrate a sense of direction and spatial awareness into real-time audio interaction, providing a more immersive virtual world experience for end users.
Overall Architecture
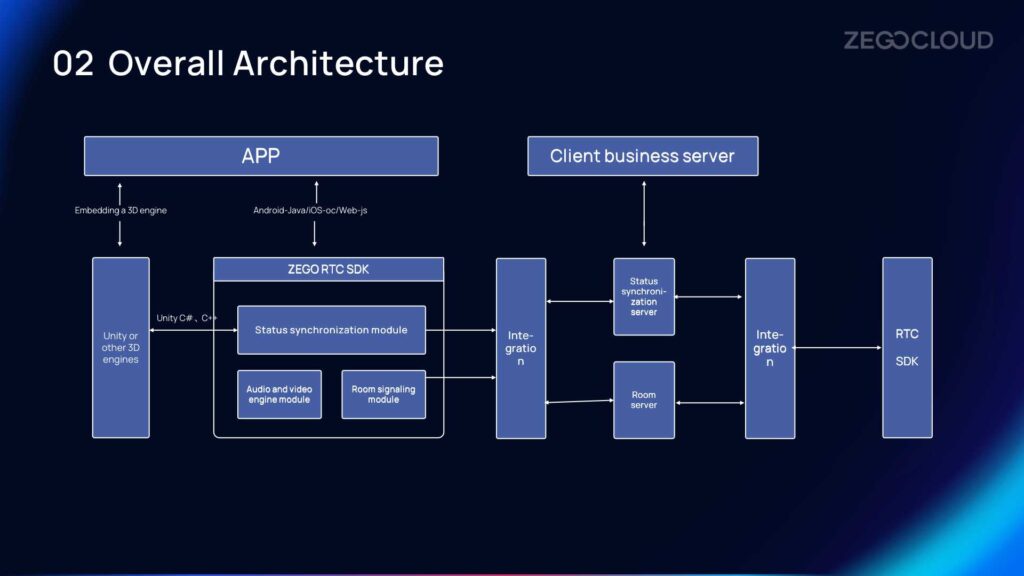
Based on the overall architecture, we can see that:
- Easy to integrate: 3D virtual world scene relies on the 3D engine, so Unity or UE is necessary for development. The ZEGO SDK is developed in C language at the bottom layer. The output interface to the outside world is C++/Unity C#, supporting mixed programming construction as a whole module. Therefore, both 3D virtual scene developers and business application developers can use their familiar programming languages without additional learning costs.
- Providing a status synchronization server for easy access to all status information: By introducing the status synchronization server provided by ZEGOCLOUD, the business side can easily subscribe to the status information of all users, so as to design relevant business logic based on this status information.
Easy to Integrate
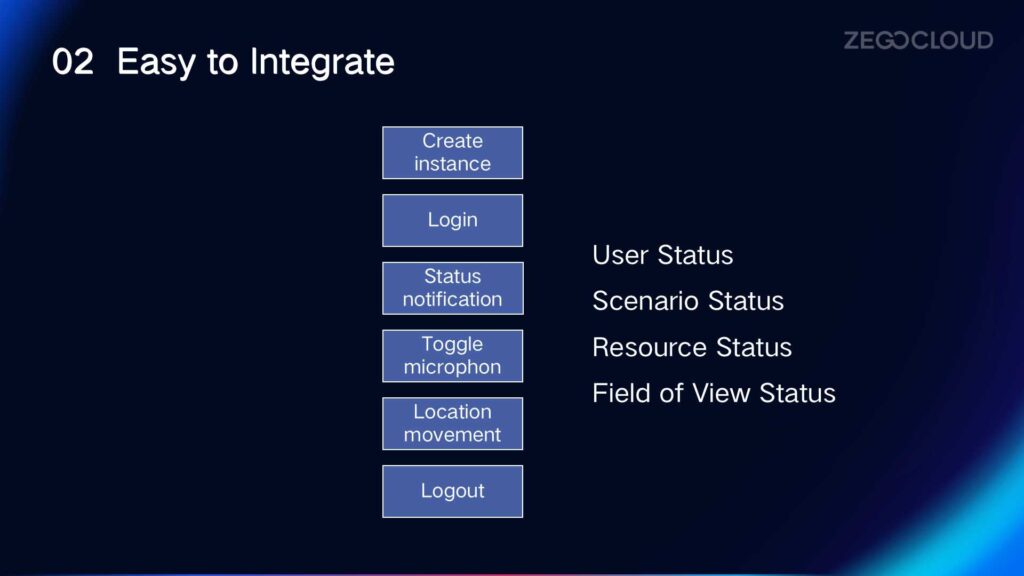
Although it may sound complex, it is actually easy to implement. After creating an instance and logging in, ZEGOCLOUD will automatically divide different types of status notifications. The business side only needs to pay attention to the notification events they need to focus on.
ZEGOCLOUD Virtual Avatar
Avatar Product Capabilities
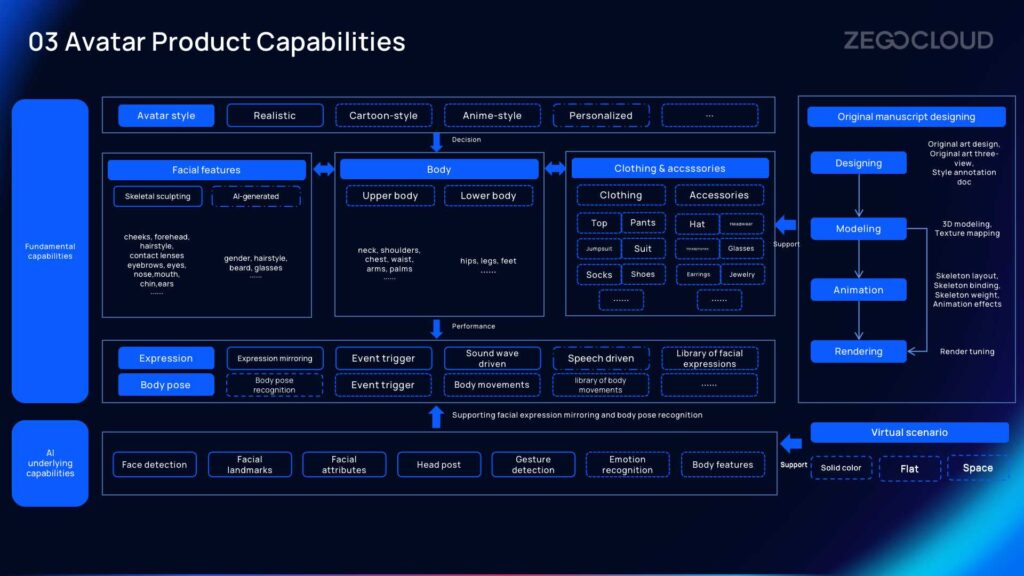
With the development of AI, especially the widespread use of applications like ChatGPT, AI-generated virtual avatars have become common. So what is the difference between AI-generated virtual avatars and ZEGOCLOUD’s virtual avatars?
The process of generating ZEGOCLOUD’s virtual avatars, shown on the right, does not rely on AI generation. The generation process of ZEGOCLOUD’s virtual avatars is more complex. And it involves stages such as modeling, design, animation, and rendering of original manuscript designing. Professional artists create original manuscript, and we have our own modeling standards and animation processes. Each step follows ZEGOCLOUD’s design specifications to ensure that the virtual avatars are complete and well-designed. Every avatar contains all the necessary body parts, clothes, accessories, and more. Combining the design specifications with AI capabilities, the virtual avatars can resemble real humans.
In summary, the most significant feature of ZEGOCLOUD’s virtual avatars is the ability to achieve fine-grained control through simple programming.
Key Underlying Capabilities

AI-generated avatar
It utilizes powerful and stable facial recognition technology to analyze and train on a massive amount of data, accurately replicating the facial features and shape of real human faces in virtual avatars.
Self-defined avatar
It allows for parameter adjustments of various facial features using skeletal animation. It combines synthesized facial features with artistic elements such as makeup and accessories, enabling natural replacements and customizations on virtual avatars.

The parameters of avatar are extensive, providing a wide range of possibilities to achieve desired effects. These adjustments can be made manually through the application programmed through APIs by developers, or even adjusted automatically using AI. When taking a photo or uploading an image, AI extracts facial features. It includes facial shape, hairstyle, etc., from the image to generate a highly realistic virtual avatar.
Facial expression mirroring and body pose recognition
Facial expression mirroring can be driven by either real-time camera or dynamic text driven. The camera-driven control relies on precise facial keypoint recognition to capture and replicate facial expressions in real-time. Body pose recognition involves real-time recognition of movements through camera input, extracting body position information and driving the avatar’s movements. While camera-driven control has certain requirements for the environment and actions, it can be utilized in many scenarios.

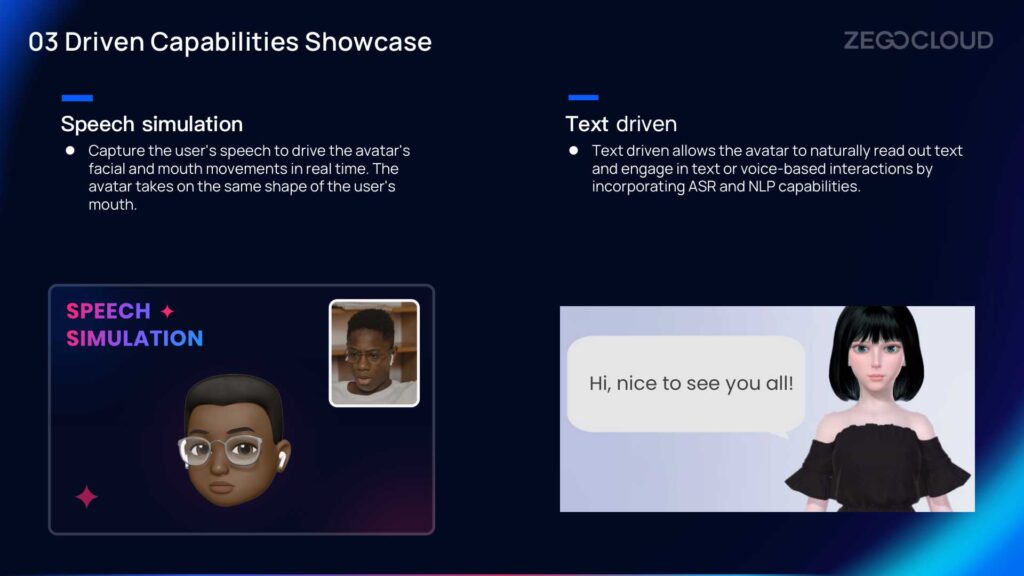
Speech & text driven
The virtual avatars are driven by speech and text inputs. Speech driven utilizes real-time analysis of voice waveform information to drive facial and mouth expressions, resulting in natural and realistic expressions. Text driven allows virtual avatars to read out text naturally and engage in text or voice-based conversations by incorporating ASR (Automatic Speech Recognition) and NLP (Natural Language Processing) capabilities.
Modeling Capabilities Showcase
ZEGOCLOUD’s design team has created virtual avatars in various styles, including realistic, cartoon-styled, and anime-styled avatars.

Integrating Virtual Avatars with RTC
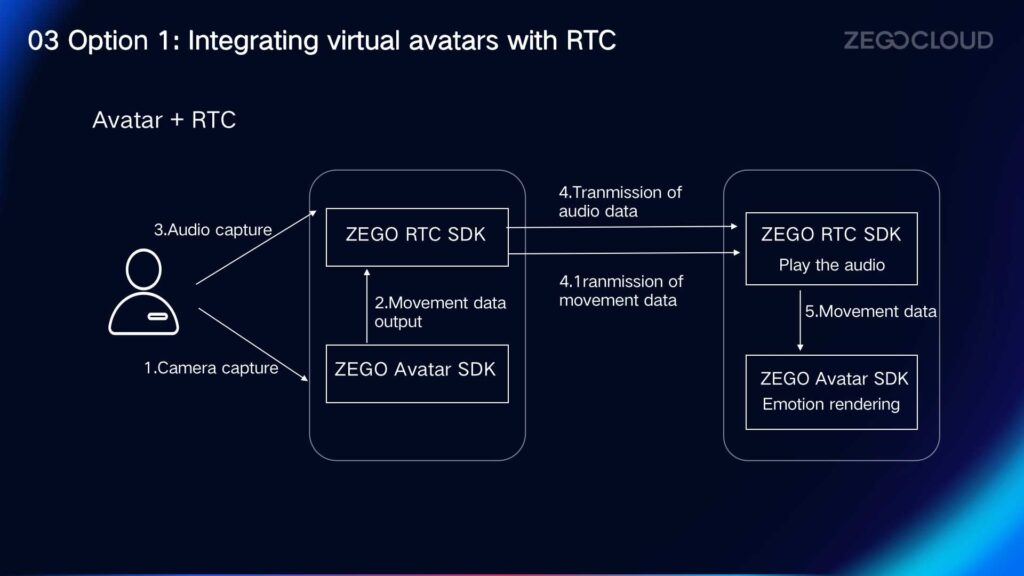
ZEGOCLOUD also provides a solution for integrating virtual avatars with RTC (Real-Time Communication). It enables multiple virtual avatars to interact within the same space. One virtual avatar can observe the movements, expressions, mouth movements, actions, and audiovisual interactions of other virtual avatars in the shared space. This integration allows users to experience the emotional changes of others in the virtual world, similar to the real world.
This solution combines Avatar SDK and RTC Express SDK. The camera captures the video, which is then transmitted to the Avatar SDK. The Avatar SDK uses AI to extract facial expression data and renders the expressions in real-time. The rendered video is then passed to the Express SDK, which handles the transmission of audio and video information. Finally, the Avatar SDK consolidates the data and outputs the rendered expressions.
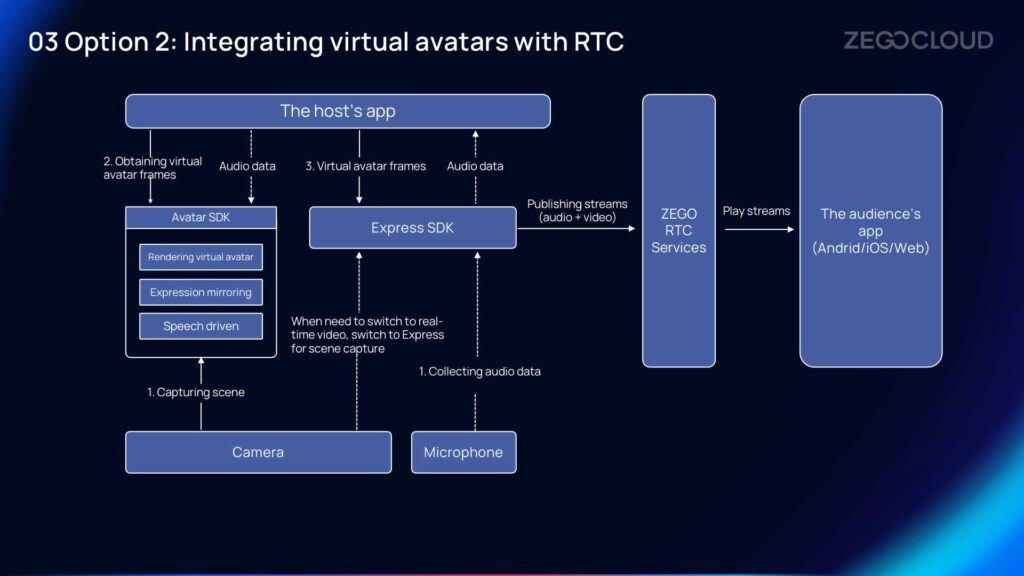
For scenarios such as live streaming, and customer service with virtual avatars, the solution in the image is more suitable. Long-term real-time rendering on the client-side, such as browsers, and webviews, can be resource-intensive, As a result, the video frames of virtual avatar is captured by the Avatar SDK, and the rendering is completed within the Avatar SDK. While finishing, the video frames and audio information are then published to the RTC SDK. Meanwhile, the RTC SDK handles the audio and video streams. The stream-playing end does not need to perform real-time rendering of the virtual avatar locally since the content is in the form of a video stream, which can be played back on any suitable device.
By exploring RTI, we gain a deep understanding of RTI crucial role in enhancing interactivity within the metaverse. These technological advancements have paved the way for a truly immersive metaverse experience. With these technological foundations in place, we are able to create more realistic, immersive, and interactive digital environments. RTI allows us to share and create content, as well as engage in deeper communication and collaboration with others. As the metaverse continues to evolve, RTI will drive us towards a future that is more interactive and innovative.
Let’s Build APP Together
Start building with real-time video, voice & chat SDK for apps today!
