








Abstract: The article will introduce a lightweight neural network approach to reduce noise. It will be a thorough explanation of the algorithmic implementation of the AI-empowered approach.
1. A lightweight neural network noise reduction approach
At present, users are often exposed to various scenes when making audio calls. The noisy background sound and transient noise often interfere with the call.
Transient noise refers to the noise with discontinuous time distribution and morphological characteristics, which is relative to steady-state noise. For example, mouse-clicking, keyboard sound, tapping sound, air conditioning sound, kitchen dishes collision sound, etc. are all transient noises.
The traditional audio noise reduction algorithm based on signal processing has a relatively good noise reduction effect for stationary noise, but for complex scenes such as transient noise and low signal-to-noise ratio, the noise reduction effect is poor or even ineffective.
With the wide application of deep learning at present, a large number of audio noise reduction algorithms based on the neural network have emerged. These algorithms can achieve better results both in noise reduction effect and generalization ability, which makes up for the shortcomings of traditional algorithms.
However, most of these approaches are end-to-end ones directly based on the frequency domain signal or time domain signal after the short-time Fourier transform. There are problems such as too complex network model and huge performance consumption, which pose a great challenge to real-time scene delivery.
Facing the above challenges, ZEGOCLOUD proposed a lightweight neural network noise reduction approach and implementation – zegocloud_aidenoise, which has a good noise reduction effect for both steady-state and transient noise, ensures the quality and intelligibility of speech, and controls the performance cost at a very low level, which is equivalent to the traditional noise reduction algorithm, and successfully covers most medium and low-end models.
In this article, we will introduce the implementation principle of zegocloud_aidenoise in detail, and how to improve the noise reduction effect and generalization ability of the deep learning algorithm under the premise of low-performance overhead.
2. The principle analysis of zegocloud_aidenoise algorithm
The zegocloud_aidenoise adopts a hybrid method combining traditional algorithm and deep learning. In order to reduce the performance overhead, it adopts the frequency domain sub-band scheme, infinitely reduces the deep learning network model, and achieves better noise reduction effect with the smallest network model.
1) Signal model
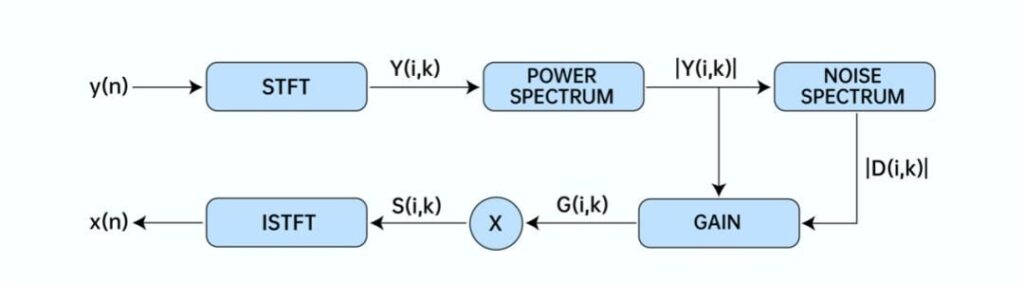
As shown in Figure 1, the traditional basic principle of noise reduction mostly adopts spectral subtraction, that is, the noise energy and the gain of each frequency point are estimated according to the spectral energy to obtain clean speech. Therefore, as long as the zegocloud_aidenoise can accurately estimate the frequency gain G, the desired clean speech signal x (n) can be obtained from the noisy microphone signal.
The derivation process of frequency point gain G is as follows:
y(n) = x(n) + d(n) ……… (1)
In formula (1), X (n) represents the clean speech signal, D (n) represents the noise signal, and Y (n) represents the signal collected by the microphone.
After STFT is performed on formula (1), formula (2) is obtained:
Y(i, k) = X(i, k) + D(i, k) ……… (2)
Where Y (i, k), X (i, k) and D (i, k) represent the frequency domain signals of y (n), x (n) and d (n), respectively. The i represents the ith time domain frame, and k represents the frequency point.
Therefore, formula (3) is obtained:
G(i, k) = |S(i, k)| / |Y(i, k)| ……… (3)
G (i, k) represents the estimated frequency gain.
Therefore, as long as G (i, k) is estimated, the speech signal S (i, k) can be estimated through the noisy signal Y (i, k).
2)Characteristic value
In order to avoid a large number of outputs and avoid using a large number of neurons, the zegocloud_aidenoise decided not to use speech samples or energy spectrum directly. As an alternative, the zegocloud_aidenoise considers a frequency scale consistent with human auditory perception – the Barker band scale, with a total of 22 subbands.
In order to better estimate G (i, k), it is necessary to select features that are more representative of speech characteristics, so as to distinguish between speech and noise. The zegocloud_aidenoise introduced a comb filter based on gene cycle indicated in formula(4), Where, M is the number of cycles on both sides of the center tap, and the time delay can be changed by adjusting the value of M.
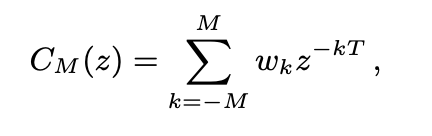
Adaptive target gain: if the coherence energy obtained by comb filter is lower than that of clean speech, adjust the target gain to limit the maximum attenuation, which can effectively solve the problem of over suppression in noisy scenes.
Using comb filter can effectively improve the harmonic characteristics of speech, reduce the inter harmonic noise, and exchange a certain time delay for better noise reduction effect.
3) CRNN network model

As shown in Figure 2, the zegocloud_aidenoise adopts hybrid method combining traditional algorithm and deep learning. The traditional algorithm performs feature extraction and post-processing on real-time data, and deep learning estimates subband gain. Hybrid can not only meet the requirements of real-time, but also adapt to the noise environment of complex scenes, bringing a good user experience to real-time communication.
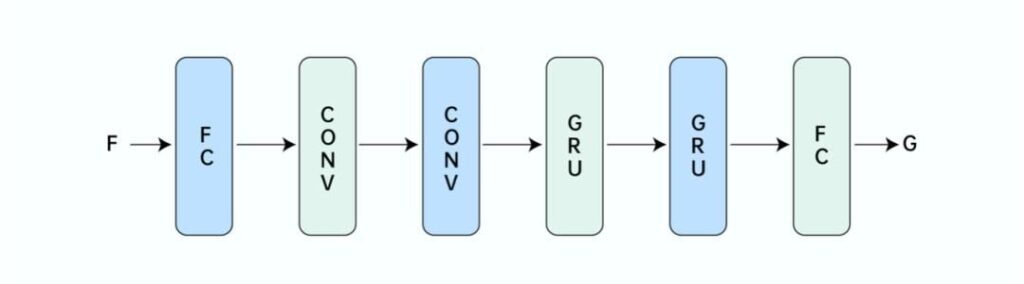
As shown in Figure 3, the CRNN model uses two convolution layers and multiple GRU layers. The use of convolution layer can further improve the effectiveness of feature extraction and generalization ability.
During deep learning training, the zegocloud_aidenoise improves the generalization of the model by applying different random second-order zero pole filters to speech and noise. The zegocloud_aidenoise also applies the same random spectrum tilt to the two signals to better summarize the different microphone frequency responses. In order to achieve bandwidth independence, the zegocloud_aidenoise uses a low-pass filter with a random cut-off frequency between 3 kHz and 16 kHz. This makes it possible to use the same model on narrowband to full band audio.
In the training process, the design of loss function is also particularly important. In addition to the square error, the zegocloud_aidenoise also introduces the fourth power error to emphasize the cost of training estimation errors. At the same time, an attention mechanism is also added to reduce the damage to speech.
3. zegocloud_aidenoise effect and performance comparison
In terms of comparison, zegocloud_aidenoise is mainly compared with traditional noise reduction and RNNoise noise reduction, which has significantly improved both in MOS and intelligibility.
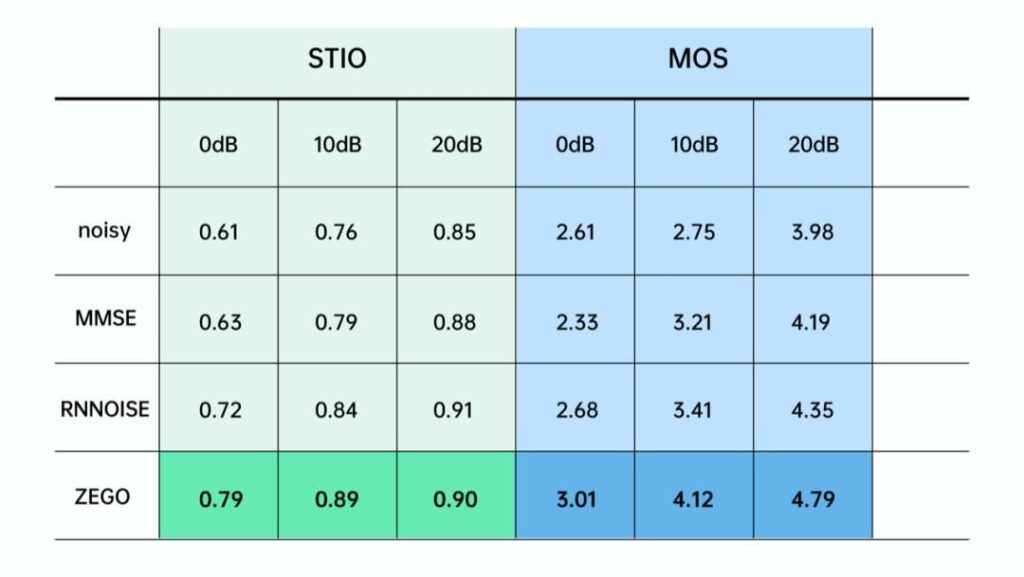
As shown above, zegocloud_aidenoise has achieved ideal noise reduction effects for different noise types and scenes. In the performance test of real-time processing, the default sampling rate is 32kHz, and the frame length is 10ms. On the iPhone 6 with a main frequency of 1.4g Hz, the CPU performance overhead is about 1%, which is equivalent to the general noise reduction of webrtc. Therefore, zegocloud_aidenoise has made great progress in terms of noise reduction effect, generalization ability, and performance overhead, realizing full coverage of models and scenes.
4. Conclusion
To sum up, zegocloud_aidenoise realizes a lightweight neural network noise reduction method, which can achieve relatively good noise reduction effect in both steady-state and transient noise environments. High quality audio noise reduction can effectively improve users’ real-time interactive experience.
At present, ZEGOCLOUD express SDK has officially provided AI noise reduction function. Developers can reduce noise when using microphones to collect sound, and on the basis of traditional noise reduction (please refer to noise suppression for details) to eliminate steady-state noise, synchronous processing of transient noise (including mouse click, keyboard sound, tapping sound, air conditioning sound, kitchen dishes collision sound, restaurant noise, environmental wind sound, cough sound, air blowing sound and other non-human noise), retain pure voice and improve the user’s call experience.
In the future, we will combine specific industries and scenarios, introduce more in-depth learning algorithms, improve the scene adaptability of products, and provide users with a better audio experience!
If you encounter noise issues when using real-time voice or video, please don’t hesitate to contact us and speak with one of our solution architects.
Let’s Build APP Together
Start building with real-time video, voice & chat SDK for apps today!
