








Advanced Audio and Video Development — Lesson 4: Necessity and Format Selection of Audio Encoding and Decoding
In the previous lesson, we learned about the three A’s for audio pre-processing. After being processed by the audio pre-processing module, sound signals are purified. Before you want to share sound signals with others, pay attention to audio ending and decoding.
Necessity of audio encoding and compression
To share audio and video data to every corner of the world in real time, one transmission tool is required, that is, network. To make good use of this transmission tool, we must pay attention to network bandwidth.
Bandwidth is familiar to netizens. It indicates the maximum amount of data that can be transmitted over a network connection in 1 second and is usually measured in bits per second (bps). Bandwidth can be divided into upstream bandwidth and downstream bandwidth, which correspond to stream publishing (upload) and stream pulling (download), respectively. If the network is compared to an expressway, bandwidth is like the width of the road, and audio and video data are the vehicles traveling on the road. The wider the road, the more vehicles are allowed to pass side by side, and the greater its transport capacity is. If the road is too narrow and too many vehicles need to pass side by side, it may lead to traffic congestion or even car accidents. Correspondingly, the higher the network bandwidth, the more data can be transmitted per unit of time. If the bandwidth is insufficient, it will inevitably result in problems such as transmission exceptions, stuttering, and even data loss, which will harm the user experience.
Now we have a basic understanding of bandwidth, let’s take a closer look at the requirements for bandwidth in audio scenarios. The digitization of analog audio signals will result in a standard raw stream of digital audio data in PCM format. Let’s first calculate how much bandwidth is required to transmit PCM data directly.
The bandwidth required for audio data transmission can be measured by audio bitrate. In the lesson “Know-what and Know-how of Video — Elements of Audio”, we have learned the concept and calculation method of audio bitrate. For example, for a file of PCM audio data with two channels, a sampling rate of 44.1 kHz, and a bit depth of 16-bit, we can use the following formula to calculate the bitrate:
Sampling rate/Hz x Bit depth/bit x Number of channels x duration (1s) = 44100 x 16 x 2 x 1 = 1411200 bps = 1.4112 Mbps (bps = bits per second)
That is to say, the upstream bandwidth and downstream bandwidth must be at least 1.4112 Mbps. The aforementioned case applies to a single audio stream. In scenarios such as a voice chatroom or an online conference, the bandwidth needs to be N times the number of co-hosting users. For some apps, such as Clubhouse and MetaWorld, the requirements on bandwidth are higher because co-hosting users are unlimited. Statistics show that the median upstream rate of the Chinese broadband network in 2021 is about 35 Mbps. Considering that in addition to audio, other data, such as video data, which requires a bandwidth dozens of times greater than that of audio data, also needs to be transmitted in actual scenarios, the cost of bandwidth is high, and the bitrate of PCM data is unaffordable.
Therefore, how to efficiently utilize bandwidth and transmit more audio data under limited bandwidth has become an important issue. Audio encoding and decoding can efficiently solve this issue.
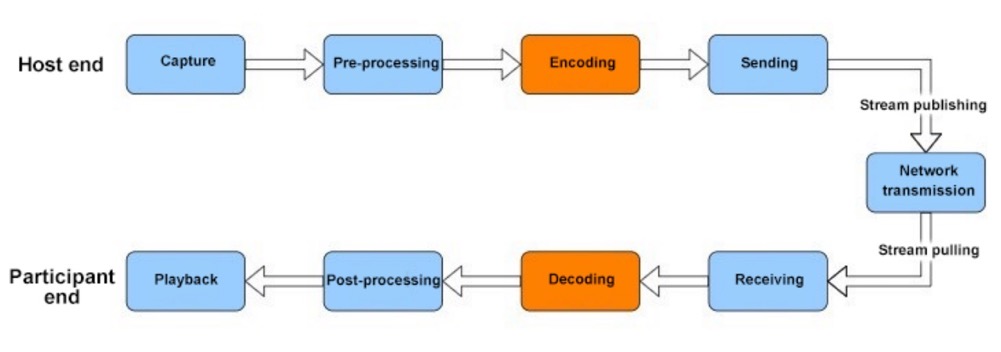
Figure 1
In terms of RTC audio and video data processing, the audio encoding module is used after the audio pre-processing module and before the network transmission module. It is mainly used to encode and compress raw audio data to reduce the data size and bandwidth consumption. (Audio decoding is performed after data receiving and can be regarded as the reverse process of audio encoding, that is, decompressing and restoring the compressed data). Common encoding algorithms, such as AAC, can compress PCM data to 1/15 of its original size. That is, the required bitrate can be lowered from 1.4112 Mbps to 0.094 Mbps, which significantly optimizes bandwidth usage. For the RTC scenario, lower bandwidth consumption indicates better adaptability to scenarios and weak networks, which is beneficial to the popularization of RTC applications and the guarantee of user experience. In addition to bandwidth optimization, encoding can also greatly reduce the pressure on storage space if you need to save audio as a file.
To sum up, the needs for “low bandwidth consumption” and “reduced storage space occupation” are the reasons why audio encoding and decoding are necessary. After learning about its necessity, we will explore why audio data can be encoded and compressed and what is the basis of the “feasibility” of encoding and compression.
Feasibility of audio encoding and compression
Audio encoding is a process of data amount compressing and reducing. However, “reducing” does not mean discarding data randomly, but reducing the “data amount” while avoiding the loss of “information” as much as possible, that is, ensuring data fidelity. If all the information of the compressed audio data can be completely decompressed and restored, the processing is called lossless compression; otherwise, the processing is called lossy compression, which has better compression efficiency and is commonly used in the RTC scenario. Today, we are going to focus on the technical points of lossy compression.
It is worth mentioning that lossy compression and lossless compression are relative to each other. Currently, any digital encoding solution is not completely lossless, just like expressing Pi with a value of 3.1415926…, which infinitely approaches to but can never be equal to the exact value of Pi.
Note: PCM is a “lossless” audio encoding method. Its principle is to sample and quantize analog audio signals along the time axis and amplitude axis, so that the reconstructed sound waveform is as consistent as possible with that of the original sound signal and in high fidelity. However, the bitrate is high, which is not suitable for the RTC scenario.
Then, how can we use “lossy compression” to achieve a high compression rate in the RTC scenario while avoiding the loss of “information” to the greatest extent? Isn’t this contradictory?
In fact, it would be more appropriate to add modifiers to “information”, that is, to avoid the loss of “useful and important information”. During data compression, the discarded data should be relatively “unnecessary” or “unimportant”, that is, “redundant”. In the RTC scenario, people are consumers of audio signals. We can make full use of the physiological and psychological characteristics of human hearing to find these “unnecessary” and “unimportant” redundant information, which are mainly divided into the following two types:
1. Audio signals beyond the human hearing range
In “Lesson 1: Elements of Audio”, we have learned that the human hearing range covers frequencies between 20 Hz and 20 kHz. Sounds with a frequency below 20 Hz are called infrasound, and sounds with a frequency above 20 kHz are called ultrasound. Infrasound and ultrasound cannot be heard by human ears. These “inaudible” sounds are the unnecessary and redundant part of audio signals. In addition, different types of signals have different frequency characteristics. For example, the frequency of voices is between 300 and 3400 Hz. If you only require voice signals, signals beyond the 300–3400 Hz frequency range can also be regarded as “redundant” and can be discarded during the encoding and compression process.

2. Masked audio signals
Sounds with different frequencies have different minimum hearing thresholds. If the loudness of a sound with a specific frequency is less than the minimum hearing threshold for that frequency, the sound cannot be heard by human ears. Moreover, the minimum hearing threshold for a sound with a specific frequency is not fixed. When a “strong sound signal” with high energy exists, the minimum hearing threshold for the “weak sound signal” in a frequency nearby increases. This phenomenon is called “frequency masking” (a masking effect), as shown in the following figure, “Frequency masking”.
In addition to frequency masking, when a strong sound signal and a weak sound signal exist at the same time, the “temporal masking” phenomenon occurs. The following figure shows that if a strong signal appears within a short period (about 20 ms) after a weak signal, the weak signal will be masked. If the two signals exist at the same time, the weak signal will be masked. After the strong signal disappears, it will take some time (about 150 ms) before the weak signal can be heard by human ears. The above three types of temporal masking are called pre-masking, simultaneous masking, and post-masking, respectively.
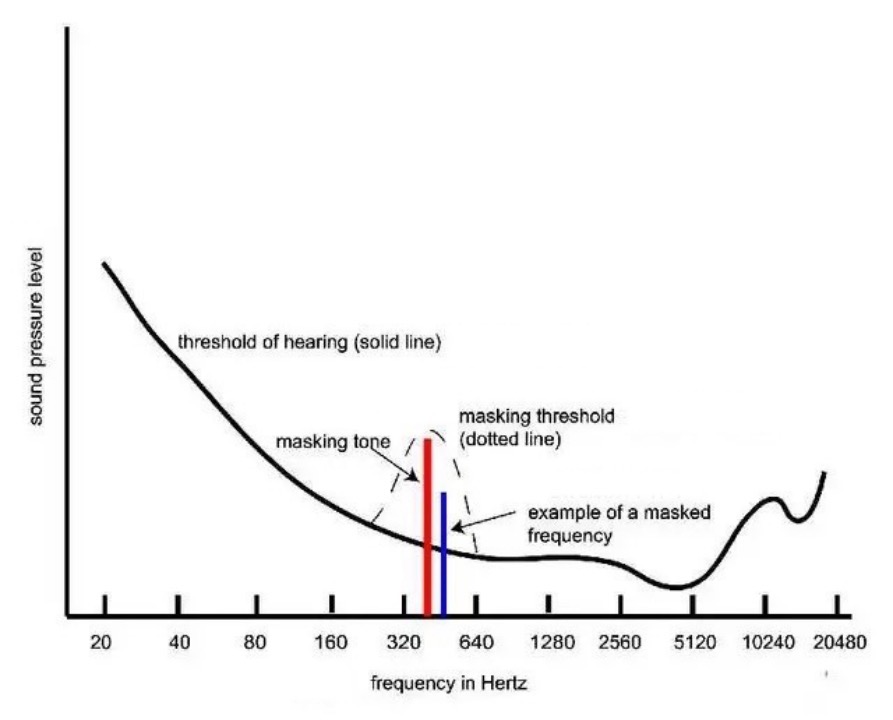
Frequency masking (source: network)
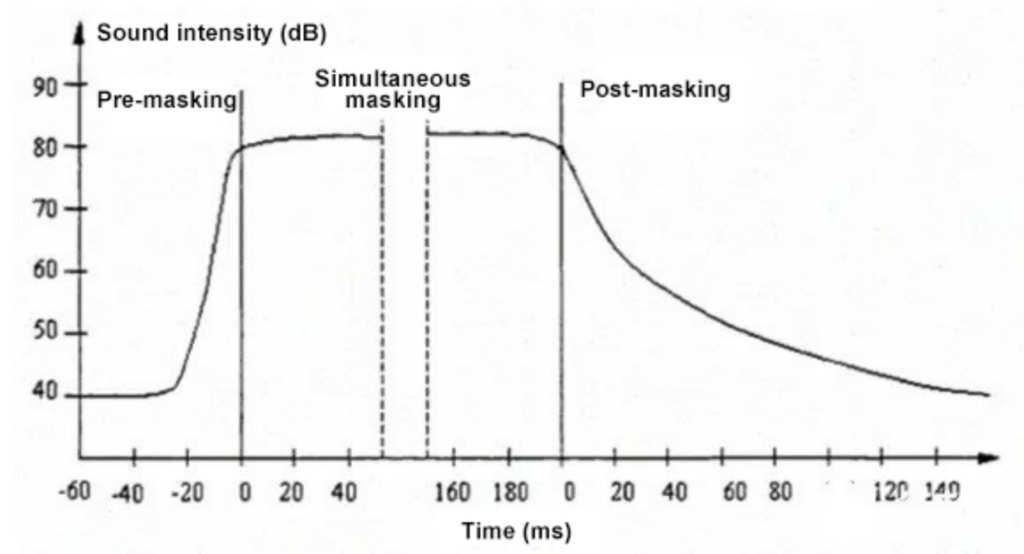
Temporal masking (source: network)
In frequency masking and temporal masking, the “masked signals” cannot be heard by human ears and can be regarded as redundant signals and “discarded” during the encoding and compression process.
In addition to “redundant” signals defined based on the physiological and psychological characteristics of human hearing, audio signals are statistically correlated in terms of temporal and frequency characteristics based on the principles of information theory. That is to say, redundant data also exists, which can also be compressed through information encoding.
In summary, we have found “redundant” elements in the sound signals, which are the basis of the “feasibility” of audio encoding and compression.
Now that we have learned the necessity and feasibility of audio encoding and compression, we will talk about audio coding formats.
The development of audio encoding and decoding has gone through many stages, from temporal encoding and decoding for voice signals to frequency encoding and decoding for music signals, and finally to “all-round encoding and decoding” that can deal with both types of signals. More information on the development history can be found on the Internet, so we will not discuss it here in detail.
Currently, many mature solutions are available. In addition to the AAC format mentioned above, common audio encoding and decoding formats also include Opus, SILK, Speex, MP3, iLBC, AMR, Vorbis, and G.7 series. AAC and Opus are commonly used in RTC applications. Today, we will focus on these two formats and other things that audio and video service developers are concerned about, such as the advantages and disadvantages of encoding solutions and how to select formats based on the scenarios.
How to select audio encoding and decoding formats
Before we dive into the details of AAC and Opus, let’s talk about how to select a suitable audio encoding and decoding format and what exactly we are “selecting” when we select an audio encoding and decoding solution.
From a general perspective, when we select an audio encoding and decoding solution, we mainly consider two aspects, namely, “usability” and “performance”. Each aspect has its sub-dimensions.
The first one is usability. In specific applications, some encoding and decoding solutions may be “unavailable” or “only available under specific conditions” due to certain “restrictions”. These restrictions mainly involve “compatibility” and “applicability”.
In audio and video scenarios, compatibility mainly refers to the compatibility with streaming media transmission protocols and platforms. A platform may be bound to a specific streaming media transmission protocol, so we usually need to consider both aspects. For example, the WeChat mini program platform supports the RTMP protocol, and the RTMP protocol supports AAC, which forms a certain restriction. Note that if the audio encoding and decoding formats supported by two platforms are different, but interoperability between them is required, it may be necessary to build a bridge through server-side transcoding.
Applicability mainly refers to “whether the supported bandwidth meets the requirements of the scenario”. Bandwidth refers to the supported range of sound frequencies. The sound frequency range (20 Hz–20 kHz) of human hearing can be divided into four bandwidth ranges: narrowband, wideband, super-wideband, and fullband, as shown in the following figure.
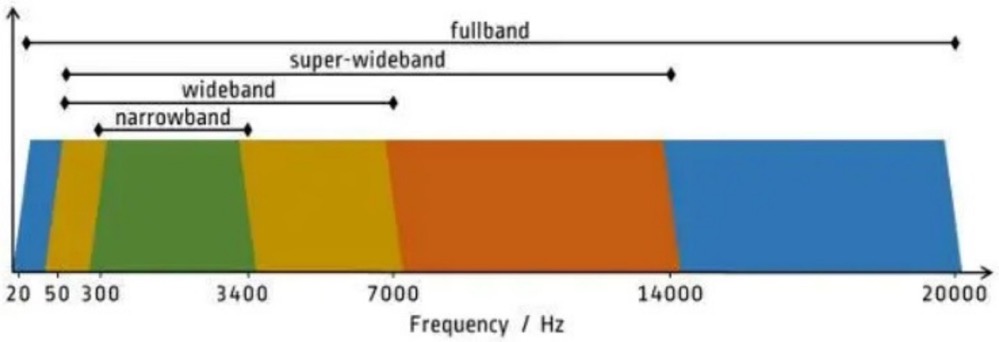
Figure 5
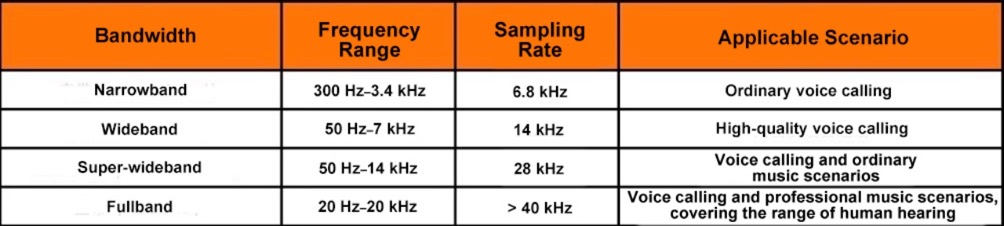
Figure 6
Based on the concepts of sound frequency, sampling rate, and Nyquist theorem that you have learned, it should be easy for you to understand the above figures. For example, the audio encoding and decoding format G.711 supports narrowband signals only. Therefore, it “can be used” to encode ordinary voices (with a low frequency) in landline and cellphone scenarios but “cannot be used” to encode fullband signals in scenarios such as live music streaming.
In addition to the basic standard of “usability”, we need to pay attention to “good performance”.
Whether a specific encoding and decoding format have “good performance” mainly refers to whether it can achieve a “perfect” encoding result in the specific scenario. In the RTC scenario, we mainly consider sound quality and delay when it comes to “good performance”.
Sound quality is a generally concerned metric and is affected by many factors. In addition to the sampling rate mentioned above, the sampling bit depth and the number of channels also matter. The greater the sampling bit depth and the more channels, the higher the sound quality. For example, AAC supports 96 kHz sampling and up to 48 channels, which makes it popular in scenarios that require a high quality of sound. Since the sampling rate, sampling bit depth, and the number of channels can affect the sound quality, the bitrate, a comprehensive metric calculated based on these parameters, also affects the sound quality. Generally speaking, the higher the supported bitrate and the wider the bitrate range, the higher the sound quality and the greater the flexibility. Those encoding formats that only support a fixed bitrate, such as G.711, which only supports a bitrate of 64 Kbps, are greatly limited in terms of the scope of application and the upper limit of sound quality.
As for the delay, it refers to the “end-to-end time” from when the audio is “captured by the host’s microphone” to when the audio is “played out on the participant’s speaker”. Delay can be caused by each stage during audio and video processing, including capturing, pre-processing, encoding and decoding, network transmission, rendering and playback. Obviously, the lower the delay, the higher the timeliness and the more likely to implement “face-to-face communication”. In co-hosting scenarios, “low delay” is even one of the most important requirements and significantly affects user experience. Therefore, it is very important to select an encoding and decoding format with appropriate delay based on the scenario.
To sum up, when we select an encoding and decoding solution, we are actually selecting the “compatibility”, “applicability”, “sound quality”, and “delay”. By considering these four factors, we can ensure the “usability” and “performance” of the selected solution. Finally, let’s compare the following encoding and decoding formats commonly used in the RTC scenario: AAC and Opus.
Selection of AAC and Opus
The MPEG-2 AAC standard was jointly developed by Fraunhofer IIS, Dolby Laboratories, AT&T, Sony, and other companies in 1997. After 25 years of development, it is widely used in various fields. Opus was jointly developed and launched by Xiph.Org, Skype, and other foundations. In 2012, Opus was approved by the IETF for standardization. Compared with AAC, Opus is “younger”. The following two figures show a visualized comparison between the characteristics of AAC, Opus, and other common audio encoding and decoding formats.
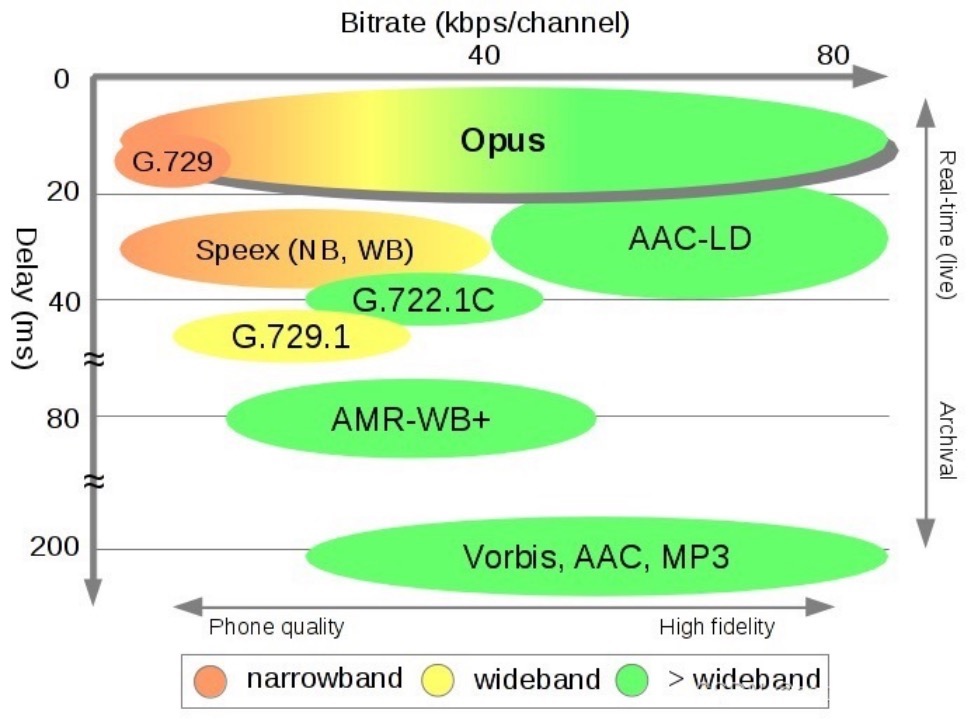
Figure 7
The above figure shows the encoding and decoding delay (Y-axis), supported bitrate range (X-axis), and supported bandwidth of each encoding algorithm.
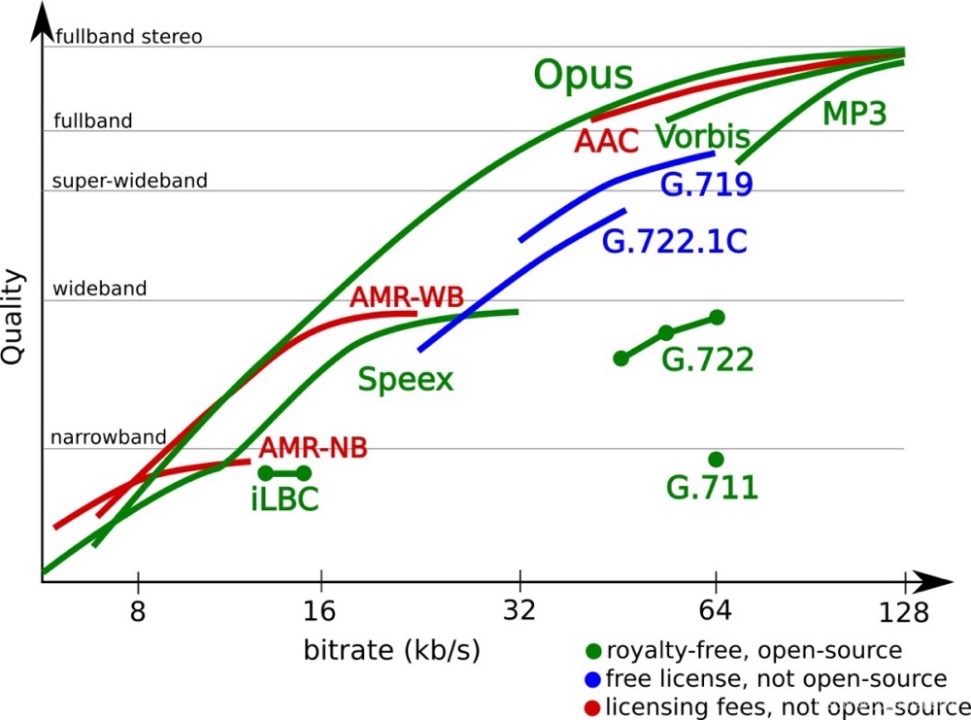
Figure 8
The above figure shows the sound quality of different audio encoding formats with different bitrates and bandwidths.
It is not difficult to find that among the listed encoding algorithms, Opus has obvious advantages in terms of “supported bandwidth”, “supported bitrate”, “delay”, and “sound quality”. It is an “all-round” format. The advantages of Opus come from its integration with two codecs, namely, the SILK audio codec and the CELT ultra-low delay audio codec, and many targeted optimization solutions. Opus can seamlessly adjust the bitrate, has extremely low, flexible, and controllable algorithm delay, and supports full bandwidth. In real-life tests, Opus has a lower delay, better compression rate, and higher sound quality than MP3, AAC, and other encoding formats. Therefore, Opus is popular in the RTC scenario. It is a must for some scenarios that are extremely sensitive to end-to-end delays, such as real-time online karaoke and multi-user online karaoke, which depend on extremely low end-to-end delays to ensure synchronization.
On the other hand, AAC takes more time than Opus in encoding and decoding and is relatively unsuitable for real-time interactive scenarios. However, it has high sound quality and fidelity. Especially in situations with an extra-high sampling rate, high bitrate, and multiple channels, AAC shows better performance. (AAC supports a sampling rate of up to 96 kHz, while Opus supports a sampling rate of up to 48 kHz. Although full bandwidth is covered by both formats, AAC can retain more details in the high-frequency range and is more suitable for live music streaming. Moreover, in addition to the standard specifications, the AAC series are optimized in terms of algorithm delay, encoding complexity, and encoding efficiency. AAC also provides various specifications. For example, the AAC Low Delay (AAC-LD) has a delay close to that of Opus, as shown in figure 7. The AAC Low Complexity (AAC-LC) has higher sound quality and encoding efficiency at medium and high bitrates and provides better compatibility. The AAC High Efficiency (AAC-HE) further improves the compression efficiency for better sound quality at lower bitrates.
In fact, the test data shows that Opus, as a “younger” encoding and decoding format, is superior to AAC in most scenarios. However, Opus still lacks a little “practical experience” and “reputation” compared with AAC, a 25-year-old format. Moreover, one of the important metrics described in the “How to select audio encoding and decoding formats” section, “compatibility”, also matters.
As a senior format developed by Fraunhofer IIS, Dolby Laboratories, AT&T, and Sony, AAC has been commonly used in various fields and is compatible with multiple hardware equipment, software applications, and transmission protocols. Opus has difficulty catching up with AAC in such aspects in a short period. For example, RTMP, a streaming media transmission protocol commonly used in live streaming scenarios, has good compatibility with AAC but does not support Opus. Most CDN service providers use RTMP as the streaming protocol by default. Some platforms, such as WeChat mini programs, support RTMP transmission only. In this case, we give preference to AAC to ensure compatible development and promotion efficiency.
It is worth mentioning that Google’s well-known open-source project WebRTC uses the open-source, free Opus as its default encoding and decoding solution, but WebRTC does not support AAC. As a result, some cross-platform audio and video applications require server-side transcoding to implement interoperability with WebRTC. Such transcoding operations increase transmission delay and the costs of development and O&M to a certain extent.
Finally, let’s sort out the differences between AAC and Opus in detail, as shown in the following figure.
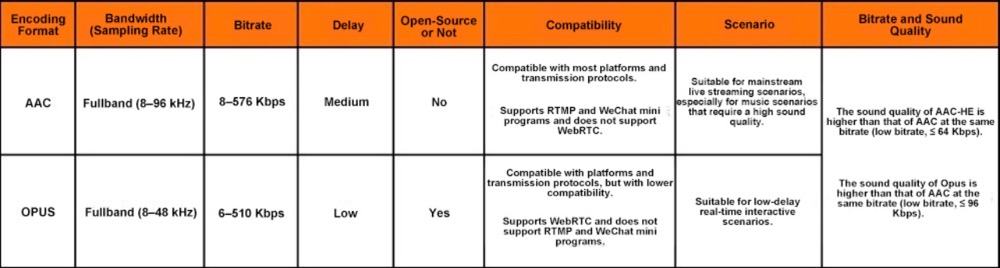
Figure 9
Summary
Finally, let’s briefly summarize the content of today’s lesson. First, we have learned the necessity (bandwidth and storage space) and feasibility (redundancy) of audio encoding and compression, and the standards of selecting audio encoding and decoding solutions (“two aspects and four sub-dimensions”). Based on these standards, we have compared the commonly used encoding and decoding formats, namely AAC and Opus, in the RTC scenario. We have also learned about their advantages, disadvantages, and applicable scenarios. With this knowledge, you will be able to select a suitable encoding and decoding solution.
So far, we have completed the learning of the know-what and know-how of audio — audio encoding and decoding section. After the capturing, pre-processing, and encoding of audio files, they can now be transmitted to every corner of the real-time network to transfer information and spread value. We also hope that everyone has notched up some gains and taken a solid step along the road of learning audio and video application development.
Let’s Build APP Together
Start building with real-time video, voice & chat SDK for apps today!
